I’ve put together a Docker setup that lets you explore two powerful LLM tools—LiteLLM and Langfuse—completely free, using local models that run on your machine. Check out the repo: https://github.com/antonbelev/litellm
What’s This About?
Not everyone has the budget or desire to pay for OpenAI, Anthropic, or other LLM API keys while they’re just trying to evaluate tools for their projects. That’s where this setup comes in. It combines:
- LiteLLM Proxy – A unified interface for working with multiple LLM providers
- Ollama – For running free, open-source models locally (Qwen2.5 and Phi-3.5)
- Langfuse Cloud – Professional-grade observability and tracing for your LLM interactions
Everything runs in Docker containers, so you can spin it up, experiment, and tear it down without cluttering your system.
Why I Built This
When exploring LLM tooling, I wanted to dig into LiteLLM’s proxy features and Langfuse’s observability capabilities. But I hit a familiar problem: evaluating new tools in enterprise environments is surprisingly hard.
Large organizations often have strict policies around Docker images, cloud API access, and security approvals. Getting budget approved for API keys just to evaluate a tool can take weeks or months. Even if you have personal API credits, you still can’t properly test how these tools would work in a production environment without navigating corporate approval processes.
This setup solves that. Savvy technical leaders can run everything locally on their own machines—no external API calls, no budget requests, no security reviews. You get real LLM responses via local models and can properly evaluate whether LiteLLM and Langfuse fit your needs before starting any formal procurement or approval process.
A quick note on Langfuse: it’s open source and offers a self-hosted option. However, the self-hosted setup requires several additional components (PostgreSQL, Redis, etc.), and I wanted to keep this evaluation environment as lean as possible. Langfuse’s cloud offering has a generous free tier that’s perfect for testing, so I went with that instead.
Getting Started
The setup is straightforward:
- Clone the repo
- Get your free Langfuse Cloud credentials from https://cloud.langfuse.com
- Copy
.env.exampleto.envand add your credentials - Run
docker compose up -d - Pull the local models:
docker exec ollama ollama pull qwen2.5:0.5b
Once everything’s running, you’ll have LiteLLM running at http://localhost:4000/ui with two free models ready to use. To access the admin UI, use the username admin and your master key (set in your .env file) as the password.
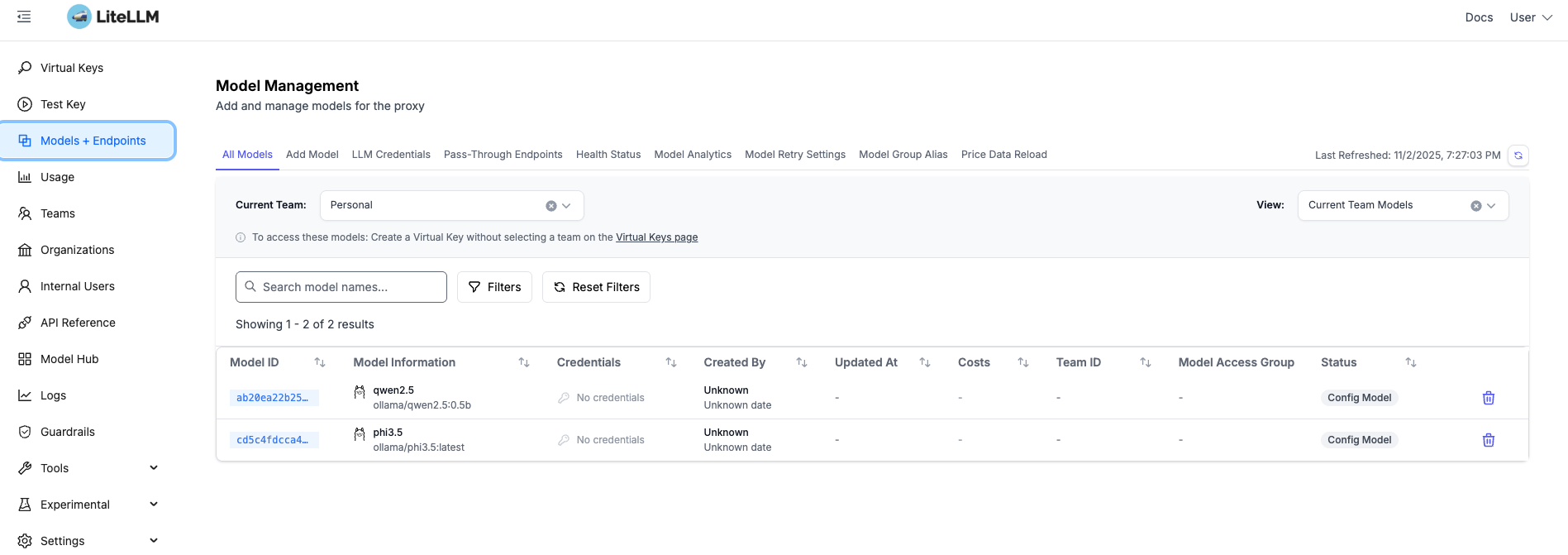
Testing the Setup
The repo includes test scripts to verify everything works. You can send requests to your local LLM proxy and watch them appear in Langfuse with full tracing.
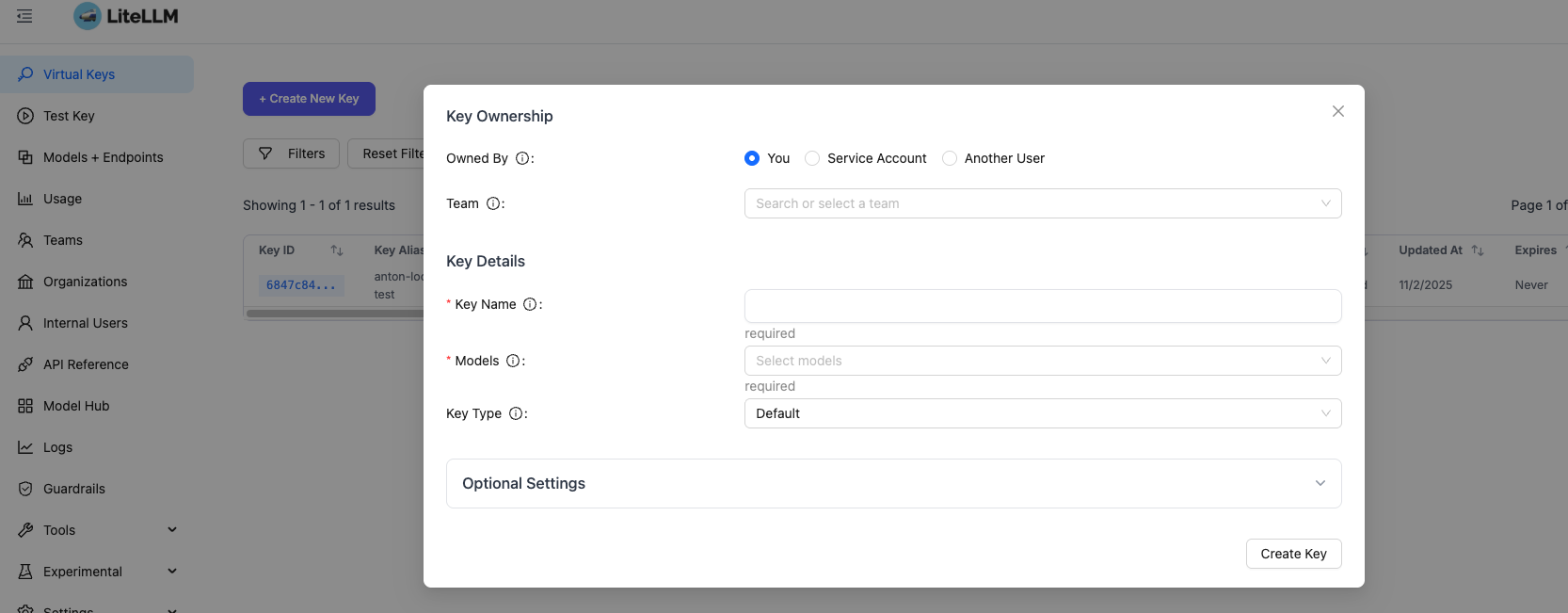
If you want to use virtual keys (LiteLLM’s way of managing API access), you can create them through the admin UI:
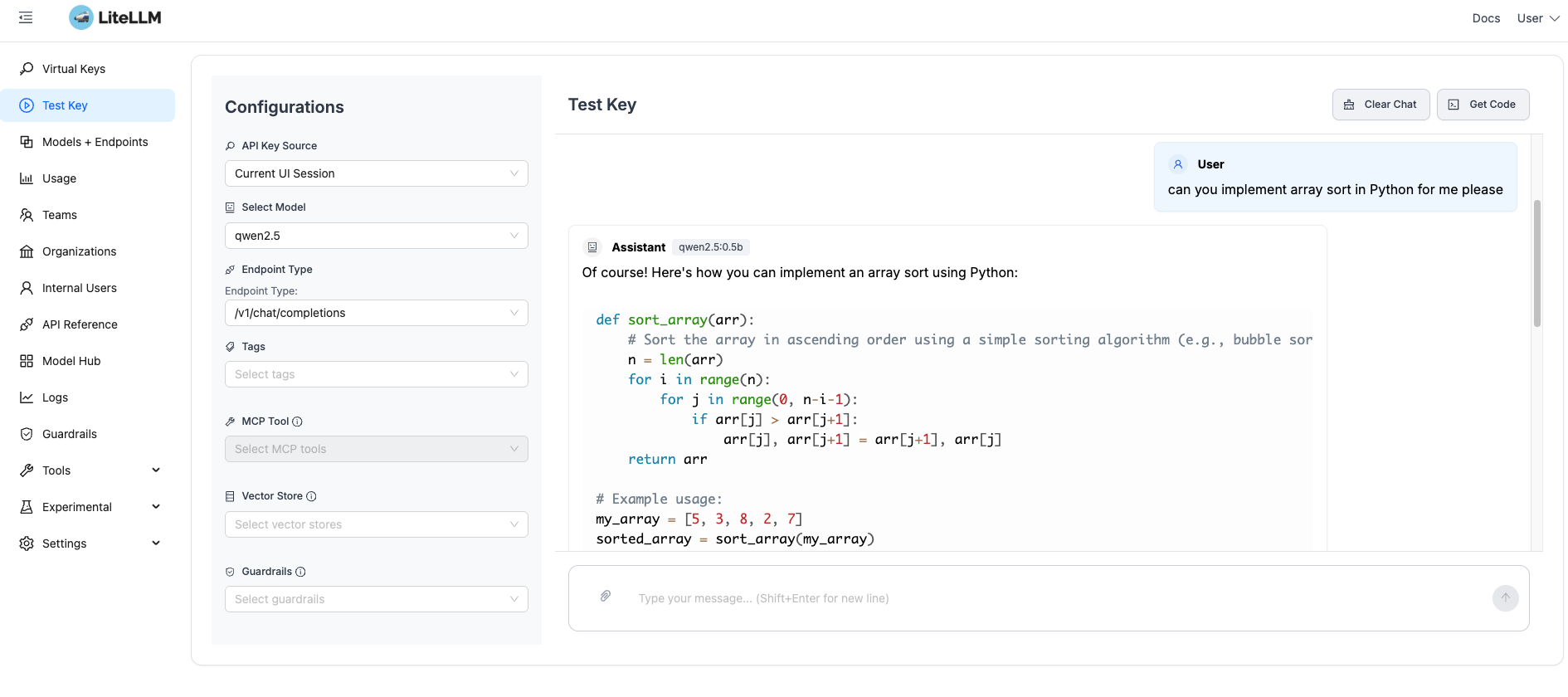
Then test your virtual key to make sure everything’s connected:
Observability with Langfuse
Here’s where things get interesting. Every request you send through LiteLLM automatically shows up in Langfuse with detailed traces. Here are some of the key features you can explore (see the full feature list in the Langfuse docs):
- User sessions – See how individual users interact with your models over time
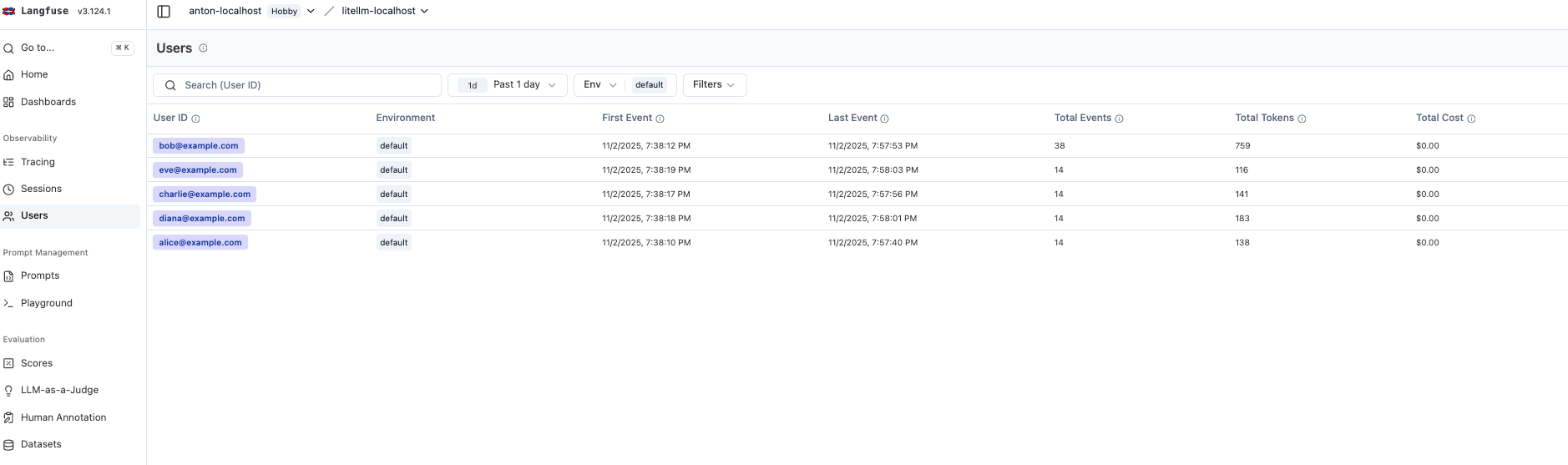
- Session conversations – Follow multi-turn conversations with full context
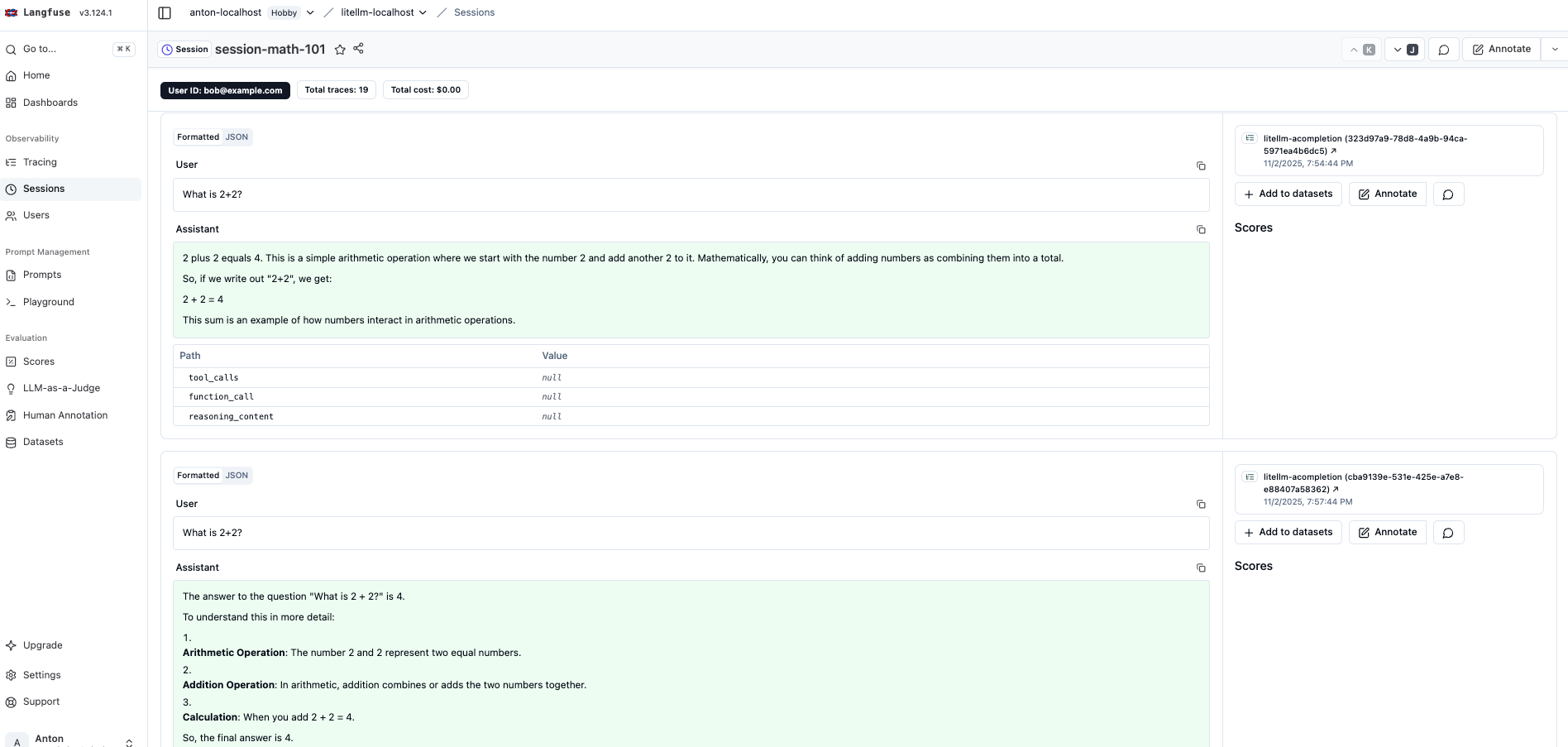
- Custom metadata – Attach tags, user IDs, and any custom data you need

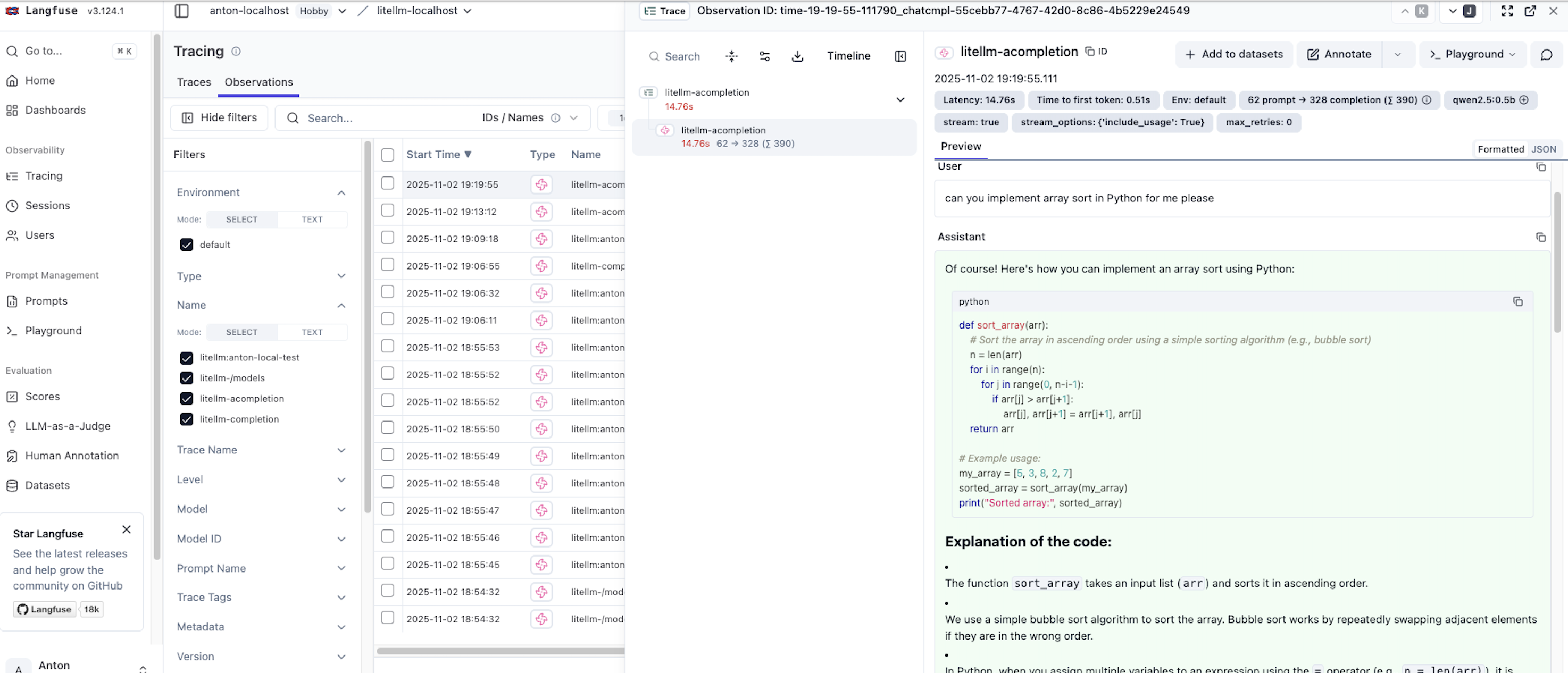
- Detailed traces – Inspect individual requests, including this example showing a Python sorting question
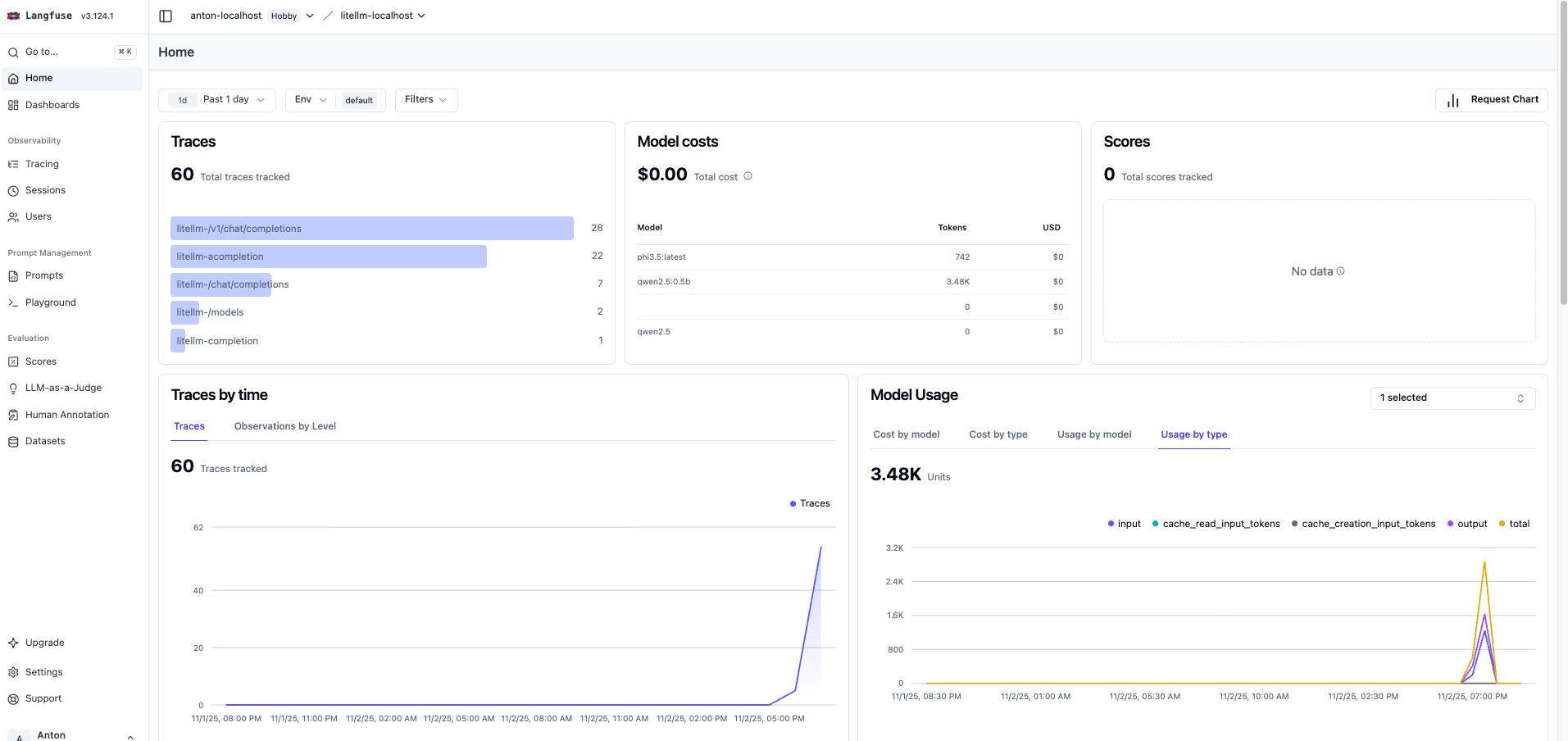
- Metrics dashboard – Get insights into usage patterns, costs (even for free models), and performance
Resource Usage
Running local models is surprisingly light on resources. Here’s what the Docker containers consume on my machine:
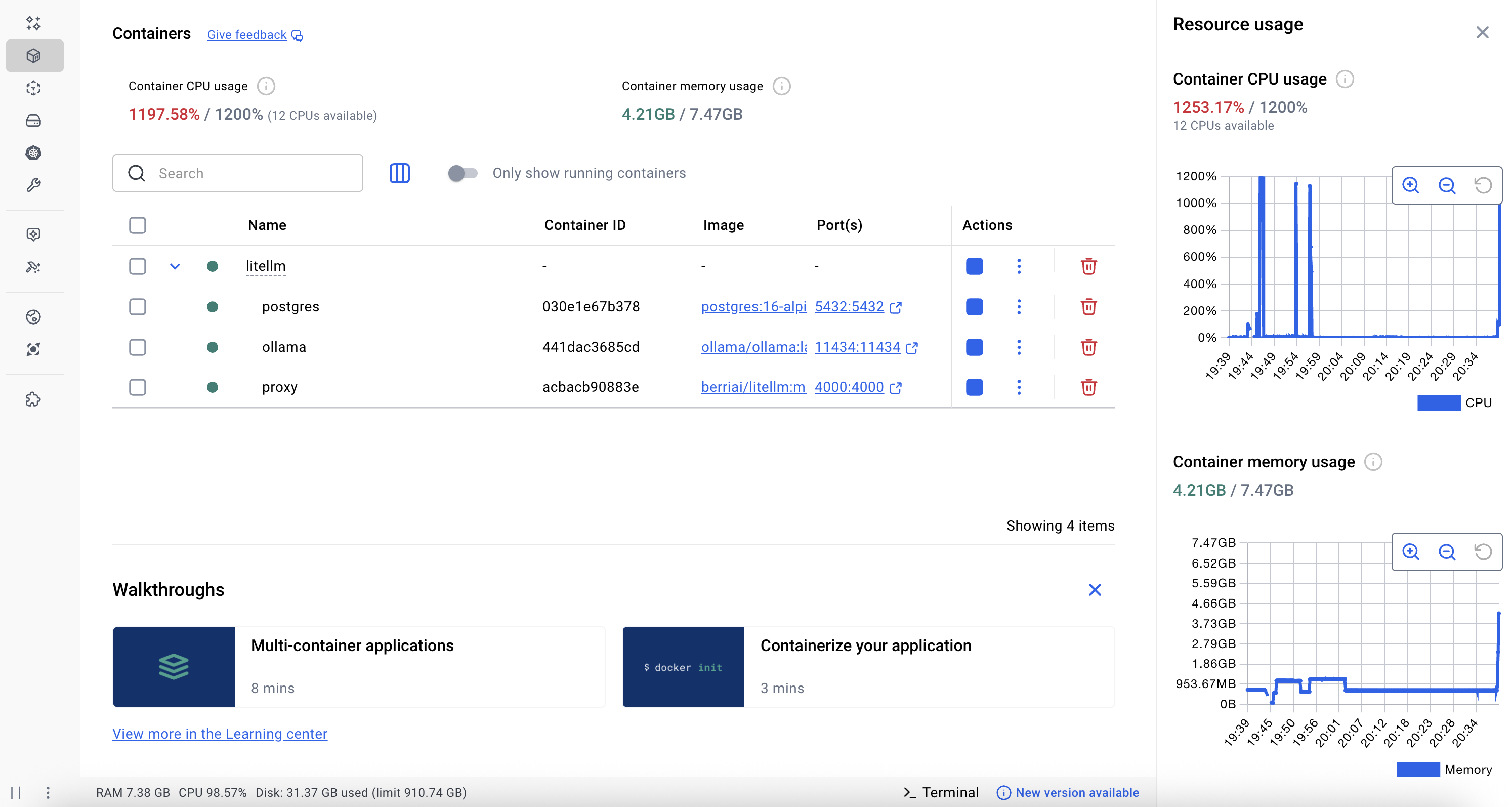
The smaller Qwen2.5 model (500MB) is particularly efficient and great for testing. Phi-3.5 (2.2GB) offers better quality responses if you have the resources.
I’m running this setup on my 2024 MacBook Pro M4 with 24 GB memory.
What You Can Do With This
This setup is perfect for:
- Learning LiteLLM – Experiment with the proxy, virtual keys, and multi-model configurations
- Testing Langfuse – See how session tracking, user analytics, and tracing work in practice
- Building prototypes – Develop LLM features without burning through API credits
- Evaluating workflows – Test your application’s LLM integration patterns locally before deploying
Looking Ahead
The repo includes configuration examples for tracking users across sessions, managing multiple models, and integrating cloud LLM providers when you’re ready to expand beyond local models.
If you give it a try, I’d love to hear what you think. The complete source code and detailed setup instructions are on GitHub:
Have questions or suggestions? Feel free to open an issue on the repo or leave a comment below.